消息在各个节点之间的传递,要保证准确性,一般要做到两点:
是接收者必须能收到
二是必须只收到一个,或者收到第二个时知道重复了,能够把重复的舍弃。
这在Storm里面是通过Guaranteeing Message Processing和Transactional Topologies这两种机制来保障的,这一篇主要介绍可靠传输。
在网络的传输层(TCP)以及链路层,为了确保数据的可靠传输,发送方在发送数据的时候会指定一个序列号,接收方收到之后返回ACK,如果发送方等待ACK超时,就会认为数据丢失,进行重传。Storm可靠传输机制的原理是基本一致的,当Spout发射数据的时候,会附带一个id,当这个tuple被消费完之后,由ACKer线程调用Spout的ack方法告诉Spout这个消息已经被成功处理,因为Spout可能会有很多task并行执行,ACKer调用的ack一定是发射该tuple那个task的acker方法,如果超过一定时间这个tuple还没有被消费完,Spout的fail方法会被调用,Spout可以根据情况选择是否重传。这个超时时间可以在Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS中设置,默认为30s,有时候我们也可以在消息处理节点上直接调用fail方法,让Spout不等到超时就立即重置发送,比如这样的场景,最后往数据库里存数据的节点,由于某种原因存储失败,就可以fail让Spout重新发这个数据。
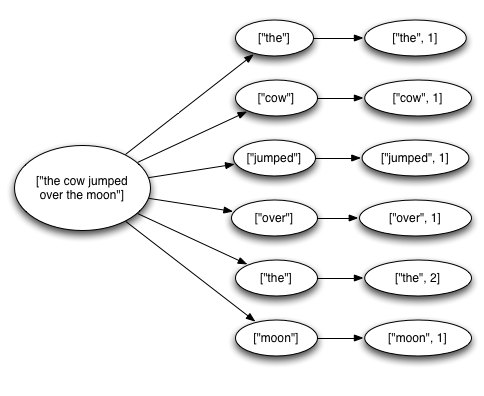
每个节点都可能收到tuple,根据这个tuple可能要发射新的tuple,这些相互关联tuple就可以构成一棵树,如下图所示,一个句子发出来,被Bolt拆分,这些拆分后再次被emit的数据就和原来的tuple形成父子关系。
Storm提供的可靠传输的API主要要求开发者做两件事:
在这些tuple之间创建link,构建这个tuple树,这个link在storm中叫做anchoring,创建的方式是在调用collector.emit发射数据的时候和输入tuple做关联
tuple的发出者要知道这个tuple有没有被成功消费,这个是通过在消费节点调用collector.ack或collector.fail方法实现。
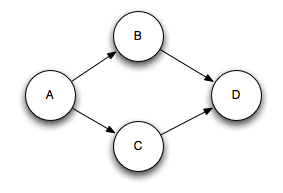
像这个图,每个节点代表一个tuple,这就是4个tuple,Spout调用collector.emit(A)把这个tuple发送出来,消费节点通过调用collector.emit(A, B)和collector.emit(A, C)在A和B以及A和C之间创建anchor。可以通过
在D和多个上级tuple之间创建anchor。这种多源的绑定会破坏树形的结构,构成了一个DAG(有向无环图)。
如果消费节点都不调用ack会怎么样?因为storm要在内存中维持各个tuple的状态和从属关系,如果所有的tuple都不被ack,那么超时之前storm就会存很多很多的数据和信息,就有可能发生内存耗尽。
前面我写的collector都是OutputCollector这个类的实例,我们经常会在Bolt里面做类似的事情,那就是接收一个Tuple、发射新的Tuple并与前面的Tuple建立anchor,然后向前一个Tuple发送ack,为了简化这种重复性的操作,Storm封装了一个BasicBolt类,并把OutputCollector也做了封装,变成了BasicOutputCollector,这样一来,用户就只是简单调用collector.emit(B),所有的anchor、ack操作就都由Storm来完成了。
当Spout发射出来的tuple被消费完之后,由ACKer线程调用发射该tuple的task的acker方法通知Spout,ACKer线程的数量应该怎么设置?这个属性由Config.TOPOLOGY_ACKERS来控制,默认为1,这个线程一般不用太多,一般情况下一个已经够用,可以参照StormUI上的吞吐量来改变它的大小。
ACKer线程维护着一个个DAG,每当有一个tuple被ACK、以及有一个新的tuple被发出,只要这个DAG发生变化了,ACKer线程就会得到通知,因为ACKer线程可能有多个,tuple又不携带ACKer线程的信息,那它怎么知道该通知哪个ACKer呢?这里有一个默认的实现,就是messageid,本文一开始举了TCP的例子,发送方发送时会指定一个序列号,作为接收ACK的标识,messageid就是Spout发某个数据的时候指定的序列号,把messageid对ACKer线程数量取模,得到的序号就是处理这个DAG的ACKer线程。另外,Spout在发数据的时候也会通知对应ACKer自己是哪一个task,等到这个消息被处理完,这个task的ack方法就会被调用。
ACKer线程会扫描整个DAG,当发现DAG上的每一个tuple都被ACK了,就认为这个消息被完全处理了。但是,ACKer要怎么扫描DAG,一个tuple树动不动就可能有上万个节点,去遍历它开销太大,Storm采用了一种很巧妙的方法,是Storm性能优化上一个关键的突破:所有的tuple在创建的时候都会被Storm分配一个64位长的随机id,下文把它标记为tupleid。前面提到,Spout在发射原始数据的时候会附带一个messageid用以可靠传输。Spout发出的tuple以及所有衍生tuple都会携带这个messageid,ACKer线程为每一个messageid维护了一个64位的字符串作为校验和(下文标记为checksum),每当有tuple被ack(消费掉)或者emit(新生成),对应的ACKer线程就会得到这个tuple对应的messageid和tupleid,ACKer把新得到的tupleid和checksum去做异或,当checksum的值变成0的时候,就认为这个DAG被完全处理了,因为只有当这些随机生成的tupleid都被异或两次(一次是生成一次是被消费)时,checksum才能是0。当然这个话说的太绝对,是有可能出现偶然情况让checksum在DAG还没有被完全处理的时候就变成0的,但是因为随机id 64位的长度,假设每秒有10k的ack,那么数学上算一下,需要5000万年才可能出现一次这种偶然。再者,即便这种偶然发生了,还有可能因为某个节点调用了fail造成整个数据的重传,从而使出现错误的几率更低。
最后看几个能够导致fail的情况,并且看看Storm是怎么处理的:
处理tuple的task挂了,所以没ack:这种情况下发送节点等待timeout,数据会被重传。
ACKer线程挂了:Spout发送的所有tuple都会因timeout而重传。
Spout挂了:这个要依赖数据源比如Kestrel或者Kafka的恢复机制。
Nimbus或Supervisor挂了:他们都是无状态的,但他们会把状态信息存储在zookeeper里面,重启之后可以读取之前的状态,继续处理。
如果可靠传输不那么重要,出于性能考虑,可以关掉可靠传输,关闭的方法有这么几种:
把Config.TOPOLOGY_ACKERS设成0,如果ACKer线程数是0,那么tuple在Spout中发出来之后立即就会被执行ack方法。
前面说了,ACKer对整个过程的管理依赖于Spout发送tuple之后附带的一个messageid,如果Spout发送的时候不指定,这个功能就没有了。
bolt中发射新的tuple的时候不要和前面的tuple建立anchor。
这里面屡屡提到DAG被消费完全,Storm里面用的词是complete,其实不仅仅所有的tuple都被ACK了才叫complete,它包含两种情况:tuple全部被ack和某节点出现了fail都叫做complete,一旦complete了,这个tuple tree就要被删掉,如果是所有tuple都被ack,那么tuple tree被删除之后继续后面的处理;如果fail了,tuple tree被删掉之后还要根据Spout的策略重新发送失败的数据。
ACKer本质上也是一个Bolt,并且使用RotatingMap来管理超时。